🦙Starten mit Llama.cpp
Übersicht
Open WebUI macht es einfach und flexibel, einen lokalen Llama.cpp-Server zu verbinden und zu verwalten, um effiziente, quantisierte Sprachmodelle auszuführen. Egal, ob Sie Llama.cpp selbst kompiliert haben oder vort kompilierte Binärdateien verwenden, diese Anleitung führt Sie durch den Prozess:
- Richten Sie Ihren Llama.cpp-Server ein
- Laden Sie große Modelle lokal
- Integrieren Sie es mit Open WebUI für eine nahtlose Schnittstelle
Lassen Sie uns loslegen!
Schritt 1: Llama.cpp installieren
Um Modelle mit Llama.cpp auszuführen, benötigen Sie zuerst den Llama.cpp-Server, der lokal installiert ist.
Sie können entweder
- 📦 Vorkompilierte Binärdateien herunterladen
- 🛠️ Oder erstellen Sie es aus dem Quellcode, indem Sie den offiziellen Build-Anweisungen folgen
Stellen Sie nach der Installation sicher, dass llama-server in Ihrem lokalen Systempfad verfügbar ist, oder notieren Sie sich seinen Speicherort.
Schritt 2: Ein unterstütztes Modell herunterladen
Sie können verschiedene GGUF-formatierte quantisierte LLMs mit Llama.cpp laden und ausführen. Ein beeindruckendes Beispiel ist das DeepSeek-R1 1.58-Bit-Modell, das von UnslothAI optimiert wurde. Um diese Version herunterzuladen
- Besuchen Sie das Unsloth DeepSeek-R1 Repository auf Hugging Face
- Laden Sie die 1.58-Bit quantisierte Version herunter – ca. 131 GB.
Alternativ können Sie Python verwenden, um programmatisch herunterzuladen
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # Download only 1.58-bit variant
)
Dies lädt die Modelldateien in ein Verzeichnis wie dieses herunter
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 Merken Sie sich den vollständigen Pfad zur ersten GGUF-Datei – Sie benötigen ihn in Schritt 3.
Schritt 3: Das Modell mit Llama.cpp serven
Starten Sie den Model-Server mit dem llama-server-Binärprogramm. Navigieren Sie zu Ihrem llama.cpp-Ordner (z. B. build/bin) und führen Sie aus
./llama-server \
--model /your/full/path/to/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ Passen Sie die Parameter an Ihre Maschine an
- --model: Pfad zu Ihrer .gguf-Modelldatei
- --port: 10000 (oder wählen Sie einen anderen offenen Port)
- --ctx-size: Token-Kontextlänge (kann erhöht werden, wenn RAM vorhanden ist)
- --n-gpu-layers: Auf die GPU ausgelagerte Schichten für schnellere Leistung
Sobald der Server läuft, stellt er eine lokale, OpenAI-kompatible API unter
http://127.0.0.1:10000
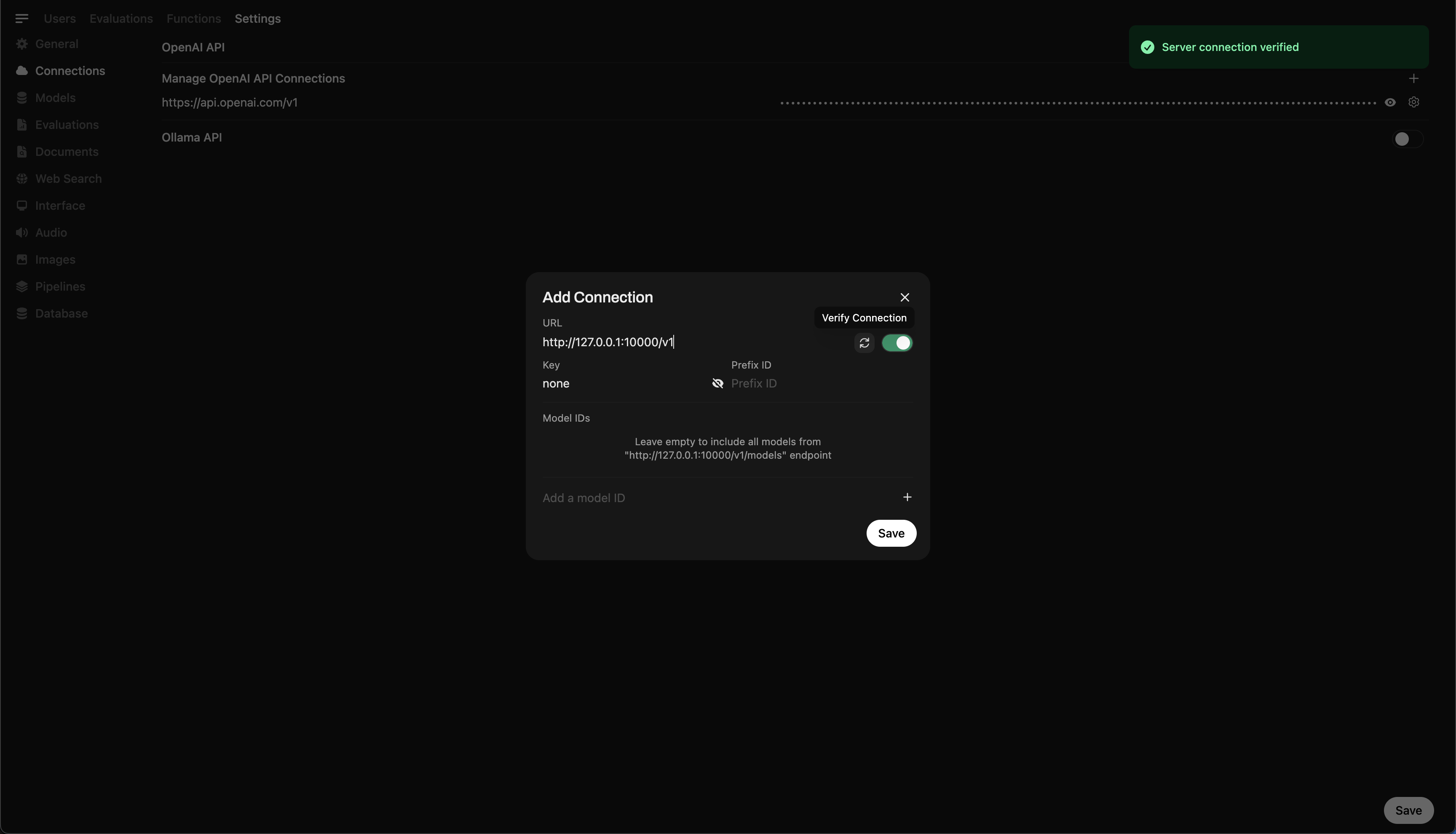
Schritt 4: Llama.cpp mit Open WebUI verbinden
Um Ihr lokal laufendes Modell direkt von Open WebUI aus zu steuern und abzufragen
- Öffnen Sie Open WebUI in Ihrem Browser
- Gehen Sie zu ⚙️ Admin-Einstellungen → Verbindungen → OpenAI-Verbindungen
- Klicken Sie auf ➕ Verbindung hinzufügen und geben Sie ein
- URL:
http://127.0.0.1:10000/v1
(Oder verwenden Siehttp://host.docker.internal:10000/v1, wenn Sie WebUI in Docker ausführen) - API-Schlüssel:
none(leer lassen)
💡 Sobald Sie gespeichert haben, wird Open WebUI Ihren lokalen Llama.cpp-Server als Backend verwenden!
Schneller Tipp: Probieren Sie das Modell über die Chat-Oberfläche aus
Sobald Sie verbunden sind, wählen Sie das Modell aus dem Open WebUI-Chat-Menü aus und beginnen Sie mit der Interaktion!
Sie sind bereit!
Sobald konfiguriert, macht es Open WebUI einfach,
- Lokale Modelle, die von Llama.cpp serviert werden, zu verwalten und zwischen ihnen zu wechseln
- Die OpenAI-kompatible API ohne benötigten Schlüssel zu nutzen
- Massive Modelle wie DeepSeek-R1 auszuprobieren – direkt von Ihrem Rechner aus!
🚀 Viel Spaß beim Experimentieren und Erstellen!